While at Brown University, I worked in Dr. Stefanie Tellex’s Humans to Robots laboratory for two years, eventually writing my honors thesis on parsing prepositional statements incrementally.
My thesis project was a model for incrementally parsing real-word referring expressions, trained and tested on human-provided data. Referring expressions are phrases used to identify a particular object in a scene by describing it and its relative position to other objects. Understanding these expressions is an important part of collaborating with a human or a machine: It would be impossible to, for example, assemble a flat-pack cabinet without being able to ask for “the metal part between the table leg and the base”, or to cook without being able to ask for “the mixing bowl near the stove”.
Humans have a tremendous advantage over machines here: our fellow humans usually adjust what they are saying based on our body language, and so we’re able to receive clarification without having to verbally ask for it. Backchannels like this are important for communication, and so we’re eventually going to need to teach machines to produce or interpret such feedback. Before we do that, though, machines need to be able to understand not just entire sentences, but parts of a sentence as well. That’s where the thesis project comes in. Here’s a video of it in action:
There are four separate parts to this project:
- The model for parsing, which provides theoretical guarantees on runtime. This is described in detail in the paper.
- An implementation of the above model in Python, available on GitHub.
- Real-world data (scenes, referring expressions, and human evaluations).
- Performance characterization.
The model and implementation are both described in great detail in the links above. Here, we’ll discuss the dataset and the presentation.
Data
It behooves us, when building a dataset for such a task, to minimize personal bias in the referring expressions generated. We do this by presenting multiple scenes, each with a variety of objects, to multiple humans through Amazon’s Mechanical Turk crowdsourcing platform. Their qualifications system allows us to control the maximum number of responses a Turker can give across all combinations of target and scenes, which makes this an attractive platform.
The scenes were all generated by scattering objects across a table, allowing our model to only consider two dimensions. We took a picture from above the table so that we could later calculate the exact positions of each object, and took a second picture from the front, looking down at the table, from the point of view of a human. Such a picture was annotated with directions, and looked like:
 Sample scene, Human's perspective.
Sample scene, Human's perspective.
The inversion of left and right were decided upon by conducting a simple experiment on Mechanical Turk, which showed that most people use left and right from the robot’s perspective. The labels help standardize this. Also, initial tests showed that users will go to great lengths to describe the target object if it is distinct from other objects in the scene. Even when the object is identical to others in the scene, they will still try to use the objects pose to disambiguate objects. (When we tested this with dice, one user identified a die by the positions of various faces.) Using plain orange cubes forced our subjects to use prepositional phrases to disambiguate between cubes, exactly as intended.
We collected referring expressions for a total of 19 scenes, with an average just shy of 14 objects per scene. We elicited five referring expressions for each one of 5-7 cubes in each scene, for a total of 798 referring expressions. We reserved 10 scenes and their referring expressions to use as a test set, and used the remaining 9 scenes to train the model.
Our model is an approximation to the complex brain processes that understand referring expressions. When we attempt to quantify its accuracy, it is important to figure out how much of the error is due to our model and how much of the error can be explained by genuinely ambiguous data. To do this, we assume that referring expressions are good if other humans are able to follow them, and so we presented each referring expression in our test set to three different human raters, again using the Mechanical Turk platform. (To prevent bias, we prevented people who had produced expressions from rating any expressions.) Here’s what that looked like:
 Another sample scene, Rater's perspective.
Another sample scene, Rater's perspective.
We realized that the human speaker and human listener accuracy is rather poor: around 79% of total responses were correct. 60% of referring expressions were unanimously interpreted to identify the correct object by three independent raters. In fact, around 7% of our referring expressions did not identify the correct object for any of the three raters. This suggests that the task is less like “identifying an object to someone standing next to you”, and closer to “identifying an object to someone over the phone”. Without the ability to read or produce body language or to refine instructions based on feedback, human accuracy suffers greatly.
Performance
Here, we’ll take a look at the performance of the system, both in terms of accuracy and speed. In order to have some perspective on the difficulty of a task or the dataset we need to have a good standard of accuracy to compare it with. In this case, obtaining the standard is simple: as described above, we had three independent human raters evaluate each referring expression, and discovered the average human accuracy on our test set is about 79%. We also used a unigram model to evaluate the entire sentence without segmentation, and also calculated the probability of selecting the correct object uniformly at random. The latter is intended to provide a minimum baseline. Here are the three baselines:
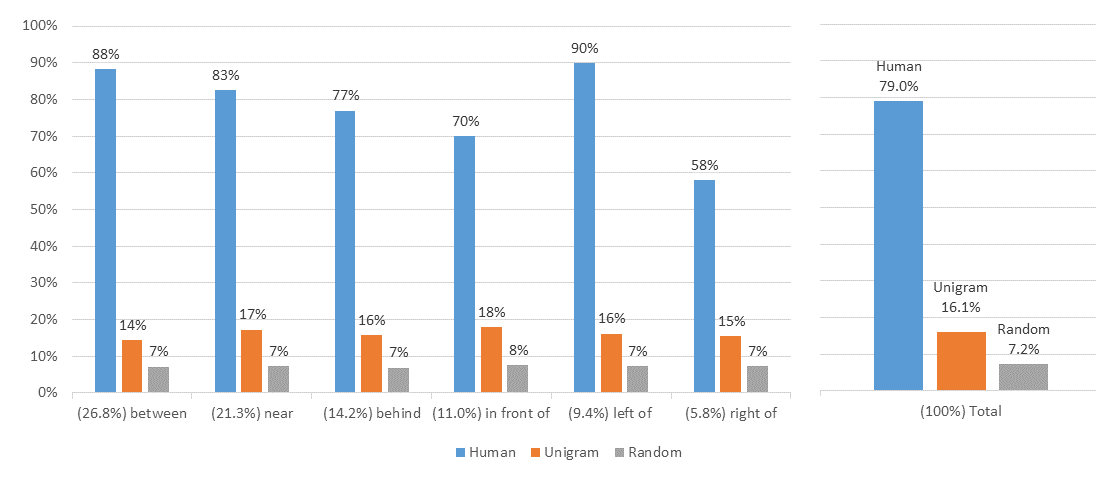 Accuracy baselines.
Accuracy baselines.
On the right, we provide the total score, weighing each example equally. On the left, we provide the score for only those examples containing a particular preposition. The percentage in parenthesis next to each preposition is the fraction of the test set that contained that preposition. They do not add up to 100% because not all referring expressions contain exactly one preposition.
We ran the model on entire expressions in the test set, and calculated the accuracy at the end of each expression. We computed a Top-1 score, in which an example is correct only if it has the highest probability of all items. We also computed a Top-3 score, in which an example is correct if it has at least as much probability as the third-highest item in the list. (To account for ties, we divided the points by the number of tied objects. This is like choosing uniformly at random from all tied objects.)
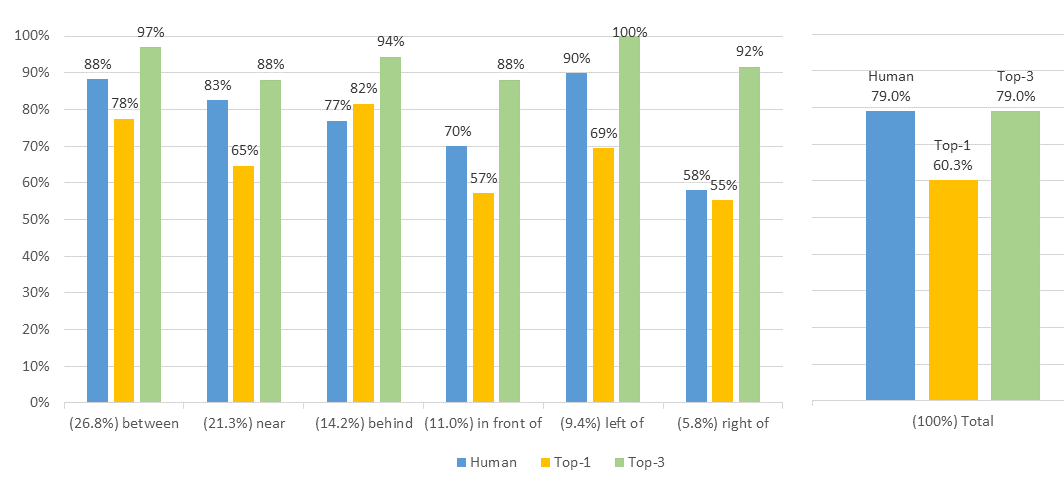 Accuracy.
Accuracy.
The overall Top-1 accuracy is about 60% and Top-3 is about 79%, respectable scores for the simple model chosen. In fact, when we only measure our model on unambiguous referring expressions (those unanimously agreed upon by three raters), we find that this jumps sharply to 70% and 85%.
So far, we have only quantified the performance at the end of the sentence. We also computed the accuracy for each step in the way, and we chart it below. Note how the score begins at around 7%, which is because we have a uniform prior over all objects. Each measure of accuracy smoothly increases, converging at the end of the sentence to the values previously calculated. The rather steep slope towards the end of the sentence is because, in typical referring expressions in English, we provide a grounding (i.e. the object relative to our target) at the end of the referring expression. (For example, we prefer “the ball near the stone” to “the ball, to which the stone is near”.)
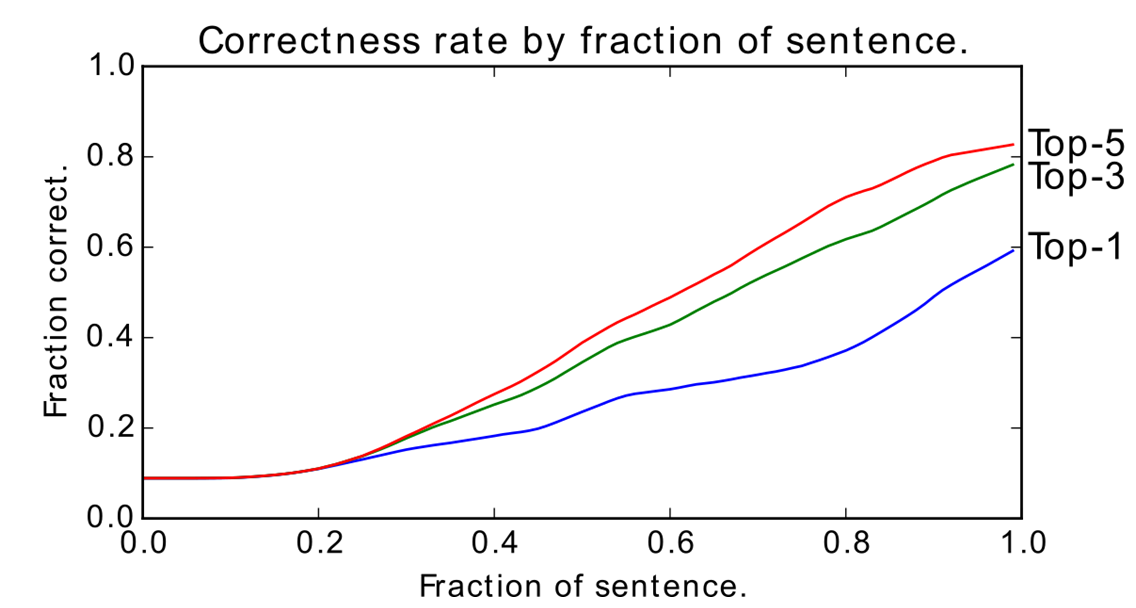 Incremental accuracy.
Incremental accuracy.
By all accounts, the performance of this simple model is good. We could add support for pointing gestures or some backchannel information and greatly improve the accuracy, or generate more data so that we can get better models for the prepositions that are used less often.
Speed is much simpler to measure. We simply measure the amount of time taken to process each word. The a good approximation to the speed of human understanding is, then, the time taken for the next word to be uttered. As long as this time is less than the time taken to utter the next word, the system is able to keep up with human speech and so is sufficiently quick for our purposes.
While evaluating the test set, we also recorded the amount of time between providing a word and receiving an updated distribution. We sorted these, and produced the following chart of the cumulative density function. As you can see, about 70% of all words are processed in 1 millisecond on commodity hardware, and about 90% in 300 milliseconds. This is fast enough to keep up with speech, and so is satisfactorily speedy.
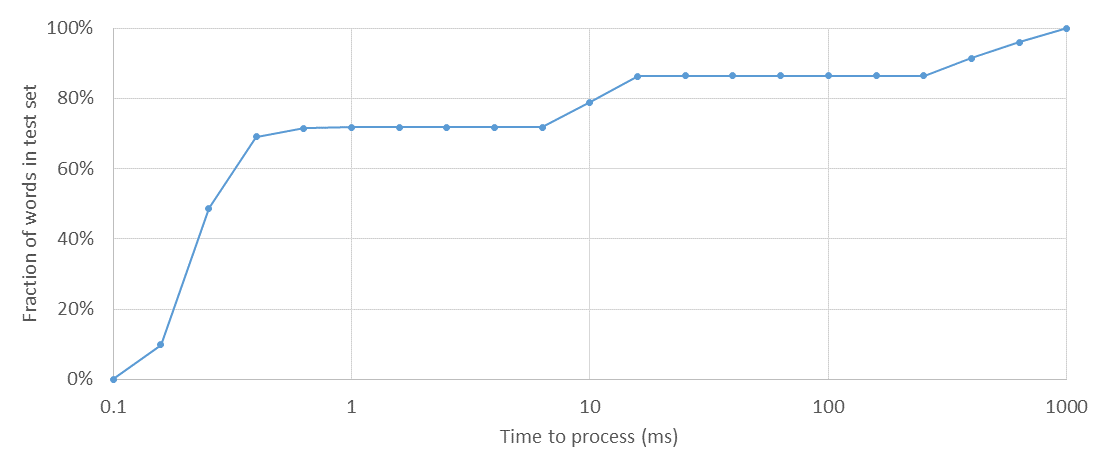 Cumulative Density Function of time taken to process next word.
Cumulative Density Function of time taken to process next word.
Conclusion
The model, its theoretical runtime guarantees, and the implementation are all extensively detailed in the paper. This chronicles the process of gathering data, and hopefully provides a more graphical approach to the model’s performance than is otherwise available in my technical writing.