Gulp is a build system for websites that uses simple stream-of-files concept to process files. The build system has a similar notion of tasks correspond to targets in ant or make, and dependencies are defined similarly.
The build process for the website is fairly elaborate, and Jekyll is only one of the steps in the build target. Here are the build targets, in approximate order of execution in a typical build cycle:
| Target | Description |
|---|---|
clean |
Delete everything in publish/ |
build-jekyll-run |
Run the Jekyll build process |
build-jekyll-html |
Copy the generated files, minifying HTML |
build-jekyll |
Clean up after the Jekyll build process. |
build-copystatic |
Copy static design assets from the source folder |
build-lessc |
Compile all .less files in transforms.lessc, remove all specifiers not used in any HTML page. |
build-jsmin |
Minify all .js files in transforms.js |
build-blogimages |
Build all the blog images |
build |
Main target, lists all above tasks as dependencies. |
default |
Default gulp target, invokes default |
And here is a dependency graph:
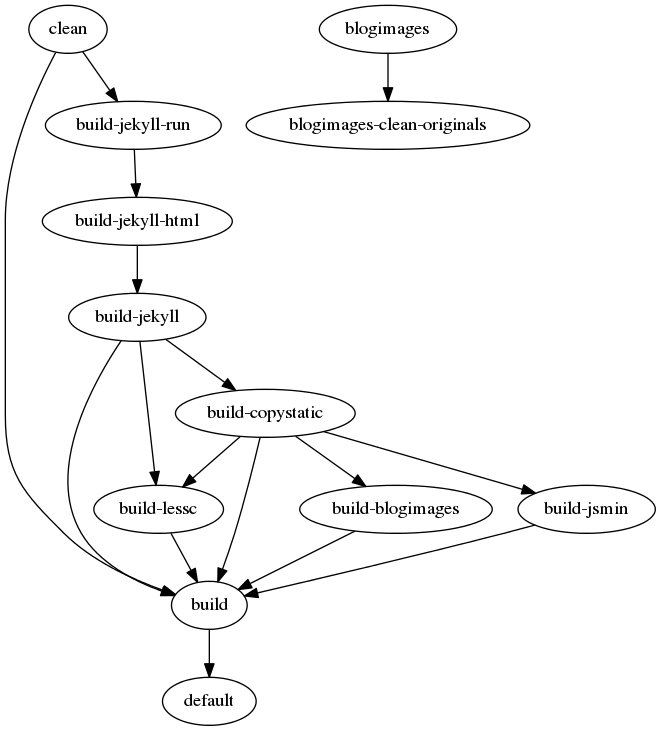
Jekyll as an intermediate step
This is an unusual use of Jekyll. Typically, all CSS, JavaScript and images are minimized and placed in the Jekyll _content/ directory. This website, however, further minimizes the generated HTML (in build-jekyll-run) and removes all generated CSS that is not used in the output (in build-lessc). These lines in the buildfile are relevant.
Abstraction
Gulp buildfiles are written in JavaScript and are processed as JavaScript code. This lets us generate the functions and parameters of each build on the fly.
With Settings
In the image building step, more than one image is generated. If you want to perform the same action once with each parameter, you map the function over the array of parameters. For example:
var es = require('event-stream');
parameters = [1, 2, 3, 4, 5]; // Arbitrary array
gulp.task('build-something', [], function() {
var tasks = parameters.map(function(num) {
return gulp.src("*.html")
.pipe(/* Your action */)
.pipe(gulp.dest("destination/"));
});
return es.concat.apply(null, tasks);
}The resulting array-of-pipes is merged into a single list using function.apply. This also prevents the function/task from returning until all sub-tasks are completed.
James Crowley discusses this technique, applied to a related problem, on his website.
With Streams
Abstracting over streams is possible with lazypipe.
Let’s say we need a function to copy files and save them with different suffixes. With lazypipe, we can write this easily:
// fileRenamer("abcdef") returns a pipe that changes "hello.ext" to "hello.abcdef.ext"
var fileRenamer = function (suffix) {
return lazypipe()
.pipe(rename, function (path) {
path.extname = "." + suffix + path.extname;
});
};
// Using the technique above:
suffixes = ["1", "2", "3"];
gulp.task('build-something', [], function() {
var tasks = suffixes.map(function(suffix) {
return gulp.src("**/*.ext")
.pipe(fileRenamer(suffix))
.pipe(gulp.dest("destination/"));
});
return es.concat.apply(null, tasks);
}In fileRenamer, instead of passing lazypipe().pipe the result of rename called with the function, we pass it a rename as a function reference and each parameter as a list after that. The documentation explains why.
We are not just restricted to iterating over parameters, we can do things like work with conditionals based on this:
function processSomeFiles (ifProcessed, ifNotProcessed) {
return gulp.src("**/*.*")
.pipe(gulpif(/* some criteria */,
ifProcessed(),
ifNotProcessed()
));We simply pass a lazypipe reference to processSomeFiles and it will pass them as appropriate. For example:
gulp.task('build-something-else', [], function() {
return processSomeFiles(fileRenamer("spam"), fileRenamer("ham"));
}gutil.noop is useful for this - it passes everything unchanged. This example only renames some files as spam, leaving the rest unchanged:
gulp.task('build-something-else', [], function() {
return processSomeFiles(fileRenamer("spam"), gutil.noop);
}Note that gutil.noop is passed as a function reference. This is because lazypipe() expects function references that it can call when it needs to.
A related problem is passing preexisting functions with custom parameters. For example, to force delete a file, the gulp syntax is .pipe(rimraf({ force: true })). We can just wrap the function call and parameters in an anonymous function to defer execution:
gulp.task('build-something-else', [], function() {
return processSomeFiles(function() {return rimraf({ force: true })}, gutil.noop);
}Files
File listing
When producing main.css, one of the build stages is running uncss, a tool that removes all unused css selectors. This step requires a list of all generated HTML files.
The easiest way to deal with this is to sidestep gulp entirely and use glob. This code returns a list of all HTML files:
glob.sync(paths.dest + "**/*.html")File existence
When processing images, we want to exclude images that already have minimized copies. To do this, we use gulp-ignore and the synchronous version of the filesystem.exists function:
.pipe(gulpIgnore.exclude, function (file) {
return filesystem.existsSync(file.path);
})Application: Image handling
Handling images for this website combines the techniques discussed above. The use case is described in Templating with Jekyll. This is the final arrangement of images:
Images are placed in folders in the same directory as posts, like this:
gauravmanek.com/_content/blog$ find . -type f
./_posts/2014-07-20-building-with-gulp.md
./_posts/_2014-07-20-building-with-gulp/dep_graph.pngThe folder names have an underscore at the front (so that Jekyll does not process the contents) and have no extension. Running gulp automatically generates copies of the file. The types of files generated can be set in transforms.imagemin. For this website, a small thumbnail and a larger full copy are produced, as shown here:
gauravmanek.com$ gulp
gauravmanek.com/_content/blog$ find . -type f
./_posts/2014-07-20-building-with-gulp.md
./_posts/_2014-07-20-building-with-gulp/dep_graph.png
./_posts/_2014-07-20-building-with-gulp/dep_graph.full.png
./_posts/_2014-07-20-building-with-gulp/dep_graph.thumb.pngFiles are only created if they do not already exist - this way, generated images can be selectively overridden.
User and Generated Files
We split all image files into two groups: those that have a matching .thumb or .full suffix and those that do not. This is done in blogImageStream. This function is used in multiple places, either to delete one group while preserving the other or to apply each transformation in transforms.imagemin.
The source code is well commented. Take a look.