When designing a GPU cluster, it is important to keep in mind an upgrade pathway. This post suggests a possible sequence of designs that will allow you to move from a four-GPU cluster to a 100-GPU cluster while ensuring that the upgrade path is clear.
The basic principle of this design is to keep track of the next limiting factor, out of: power, cooling, space, and storage bandwidth, and ensure that we adjust our design as we hit various limits.
Scaling Design
Here’s the design sequence, presented by scale. Depending on the needs of your department, you may need to tweak this progression.
Before we start, keep these points in mind:
- Use an OEM: Purchase your equipment from a specialist vendor; in the US, consider Exxact or LambdaLabs. Starting a vendor relationship will greatly help you as you scale up. Expect to pay a 10–20% premium over parts cost, and insist on a three-year warranty.
- Rackmounts: Ensure that all machines are rackmountable, including the UPS! Server racks will become essential as we scale.
- Optimize average performance/cost: When calculating price-to-performance ratio, divide the total GPU FP-32 compute capability by total cost of the server. Do not blindly select the highest-capability server GPU (those tend to have poor price-performance ratio).
4 GPUs (US$12k)
We start with our very first pair of machines. Here’s how we arrange them:
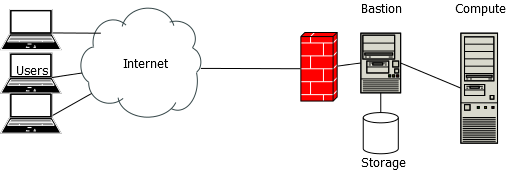
We split the responsibilities into two machines:
- A bastion host provides persistent storage (over NFS), firewall, and routing services to the compute server.
- A compute server provides GPUs and enough local resources to run them.
Users log in to the bastion server, which forwards them to the compute server. The chief advantage of this arrangement is that all compute machines appear uniform to users. This also makes them ephemeral, which allows us (once we scale the system) to take them down and replace them with minimal disruption to service.
When designing the bastion, keep these in mind:
- Network interfaces: It should have at least two network interfaces; one to the internet and the other to the compute server (and eventually the switch). 1GbE is sufficient for this.
- RAM: Ensure there is at least 16GB of RAM in the bastion host for the NFS server to maintain a cache.
- Hard Drives: The bastion stores data on spinning hard drives. When configuring, use some sort of fault-tolerance like RAID 6 or a ZFS pool. Spinning drives are cheap enough that you can begin with 4x3 TB drives for 12TB nominal capacity and 9TB actual (after parity).
- PCIe Slots: Ensure there are at least 8 PCIe lanes available in case we need to add a data backbone network.
GPU servers:
- RAM: At least one and a half times as much system RAM as GPU RAM, ideally twice as much.
- Local Storage: a SATA/M.2 SSD is sufficient; a PCIe SSD will likely not provide significant gains in this application because the PCIe network will be under heavy load moving data from the system RAM to and from the CPU. I recommend an SSD at least twice the size of your largest expected dataset; 1TB SSDs hit a good price-to-size ratio.
4–16 GPUs (US$50k)
Now we start scaling up! At this point, we are expanding from one compute machine to four machines.
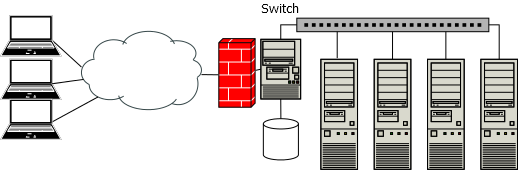
At this scale, we add a switch to provide routing between the bastion and the compute hosts. A 24-port gigabit ethernet switch is still sufficient at this scale; a large NFS cache on the client machines will, once the working set is cached, provide sufficient read performance.
We also add an uninterruptible power supply for the bastion host. A 250VA system will allow the bastion host to remain online through temporary power brownouts or circuit resets. We do not provide battery backups to the compute servers because UPSes capable of delivering the required wattage tend to be very expensive, and the bastion can bring them back online with Wake-On-LAN packets.
16–32 GPUs (US$100k)
This is the regime under which space, cooling, and power are limiting factors. This is also the point where co-locating servers in a datacenter makes sense.
Cooling is the easiest to analyze: a standard 1440W GPU server, under maximum load, requires 5000 BTU/hr of air-conditioning power. You should consult your facilities department for this; a general rule of thumb is that an office building can dissipate at most 20000 BTU/hr. Moving to a datacenter is the cheapest fix for this.
A general rule of thumb is that a single 110V/20A circuit supports two servers; now that we have four–eight machines, we are likely exceeding the number of available power circuits. Adding power circuitry is expensive and depends on the particular building; once again, moving to a datacenter will fix this problem.
Rackmounting
Rackmounting the devices allows for much easier wire management, better cooling (through consistent airflow), and much more space-efficient housing. It is also mandatory if you want to co-locate your machines in a datacenter. Here’s the cost breakdown:
Assuming that your datacenter imposes 42U (standard height unit) limit on the height of your rack, each computer is 4U, and the switch and UPS are each 2U, you can fit a total of 8 compute machines, the bastion, UPS, and switch on a single rack. Expect to pay about $1k for a high-quality 42U (standard height unit) extended-depth (for GPU servers) server rack.
Also assuming that your GPU servers draw a maximum of 1440W each, a 21kW three-phase to one-phase converter power distribution unit will allow you to power 15 GPU servers for a cost of about $1.3k. By locating racks in adjacent spaces you can amortize the cost of two PDUs over three racks.
Datacenters charge a colocation fee for servers. When moving your servers to a university-run datacenter, expect to spend about $500/rack/month; this price should include power, cooling, security, environmental monitoring, and (occasional) minor service events. Commercial datacenters charge substantially more, especially for extended-depth racks and service events.
Offsite backups
At this point, you should also start running offsite backups. Use a cheap NAS (e.g. a Synology) and run incremental backups nightly. An article on configuring this is forthcoming. Purchase enough storage to hold up to 4x the primary storage of the cluster, and house this machine offsite; preferably in a different zip-code. Test backups often and report backup exceptions.
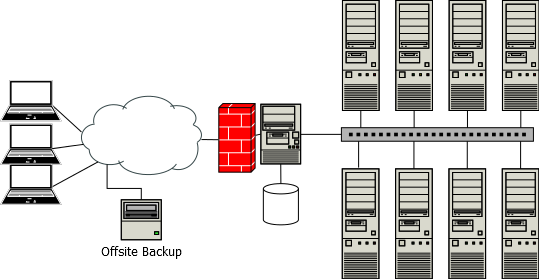
32–64 GPUs (US$200k)
This is the regime where you move from one rack to three. Remember to amortize the PDU over multiple racks, and consider buying (relatively) cheap 12-port switches to simplify network cabling between racks.
In this range, it is likely that the network throughput is the limiting factor. To increase the NAS throughput:
- A cheap and easy way is to install a second network card in your bastion host and split the LAN into vLANs using a managed switch.
- Install a second network card in your bastion host and purchase a second managed switch to split the LAN.
- For a little more money, you can upgrade the backbone switch and the bastion host to use 10GbE, and leave the remaining connections at 1GbE (this requires a managed switch or a router.)
You should use past performance data to determine what the bottlenecks in your operation are before making the decision.
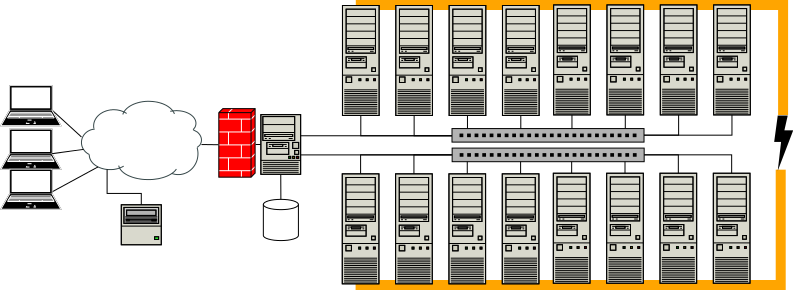
64++ GPUs
At this point, we are outside my range of expertise. From my research key changes in this step should be:
- separate the data hosting from the bastion host by having dedicated NAS host machines
- have multiple bastion hosts to prevent bottlenecking
- add a second network for data
- add a scheduler to automatically distribute jobs and run them at scale
Special upgrades
InfiniBand data backbone network
If you have write-heavy workloads (on a GPU cluster?), or are reading from a dataset much larger than you can reasonably provide a caches for on your compute servers, you may want to add a data backbone network that uses a faster interconnect. User SSH connections and all other data flow through the gigabit network; this secondary network will only be used for data.
A common trick (for the fledgeling cluster) is to purchase one or two-generation old InfiniBand hardware from eBay or resellers. (In 2019, with 100GbE InfiniBand available, it is possible to buy 10- and 40-GbE InfiniBand PCIe cards and switches for pennies on the dollar.) It is worth getting a professional systems administrator to help select parts and configure this option, if chosen.
I suggest tracking performance and utilization before taking this expensive step; 10GbE might be a sufficient compromise.